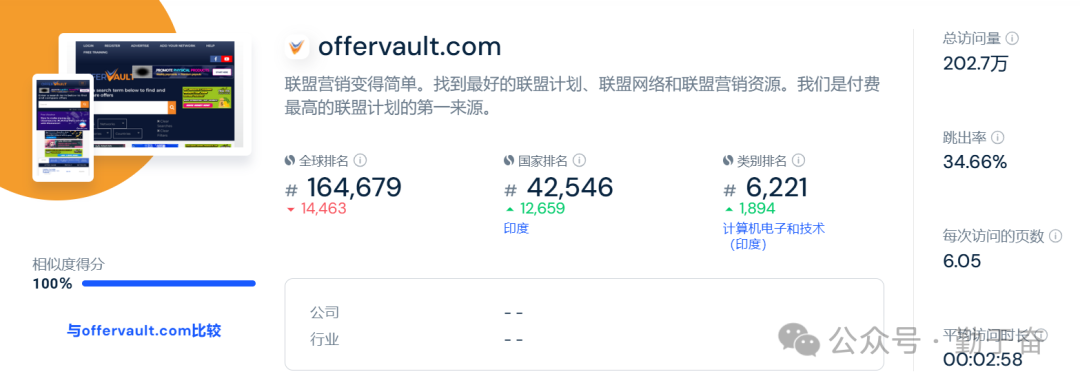
今天上Google Search Console看了一下,原来这个文件已经不存在了。
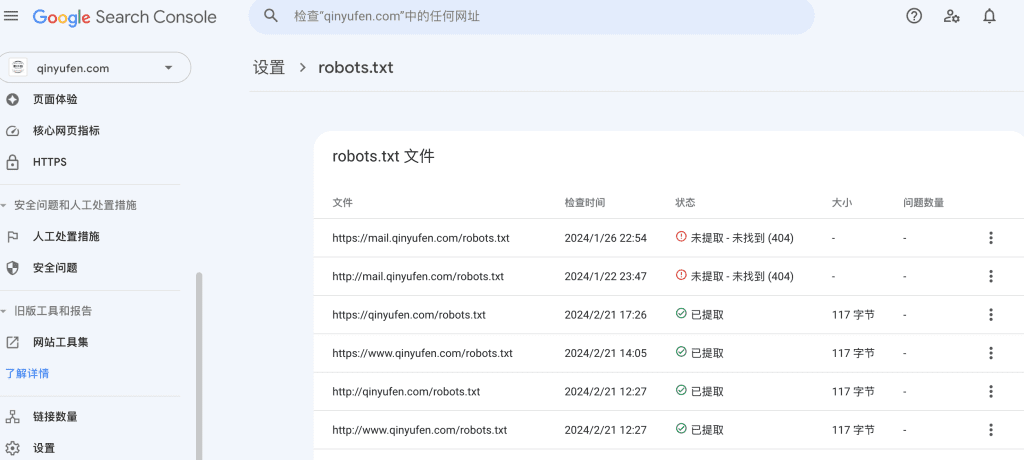
不存在是因为之前网站被破坏了,所有文件都丢失了,后来把网站重新弄好之后,忘记更新这个文件了,今天把这个文件重新整理之后又上传了。
那么rebots文件是干嘛用的?今天我给介绍一下
一个良好的robots.txt文件应该清晰明了地指示搜索引擎蜘蛛哪些页面可以抓取,哪些页面不应该抓取。以下是一些常见的robots.txt文件写法的建议:
- 允许所有页面被抓取:
User-agent: *
Disallow:这表示允许搜索引擎抓取网站上的所有页面。
- 禁止所有页面被抓取:
User-agent: *
Disallow: /这表示禁止搜索引擎抓取网站上的所有页面。
- 指定特定目录不被抓取:
User-agent: *
Disallow: /private/这表示不允许搜索引擎抓取以/private/开头的页面。
- 指定特定页面不被抓取:
User-agent: *
Disallow: /example.html这表示不允许搜索引擎抓取名为example.html的页面。
- 指定特定搜索引擎不抓取特定页面:
User-agent: Googlebot
Disallow: /private/这表示只有Googlebot不允许抓取以/private/开头的页面。
确保在编写robots.txt文件时遵循以下几点:
- 每个
User-agent和Disallow指令之间使用空行分隔。 - 使用
User-agent: *表示适用于所有搜索引擎爬虫。 - 使用
Disallow:表示允许搜索引擎抓取所有页面。 - 使用
Disallow: /表示禁止搜索引擎抓取所有页面。 - 确保robots.txt文件位于网站的根目录下,并且可以通过
www.example.com/robots.txt访问到。
请根据您的网站需求和策略编写适合的robots.txt文件内容。